Uma Continuação Necessária
No meu artigo anterior, eu defendi que a orquestração é o diferencial entre uma simples chamada de API a um LLM e uma aplicação de IA Generativa de nível empresarial. Eu apresentei o LangChain como o nosso maestro nessa orquestra. Agora, é hora de mergulharmos no módulo mais crucial dessa orquestração: o Retrieval-Augmented Generation (RAG).
Se a orquestração é a arte de guiar o LLM, o RAG é a técnica que garante que ele seja fiel, factual e atualizado, transformando o LLM de um gênio da ficção para um especialista em seu domínio de dados.
Minha experiência me mostrou que, por mais avançado que seja um modelo (GPT-4, Gemini ou qualquer outro), ele está limitado pelo seu corte temporal de treinamento. Se o usuário perguntar sobre o "documento interno Y" ou o "relatório de vendas de ontem", a resposta padrão será uma "alucinação" plausível, mas incorreta. O RAG é a nossa solução estrutural contra isso.
O Ciclo de Vida do RAG: Quatro Etapas Fundamentais
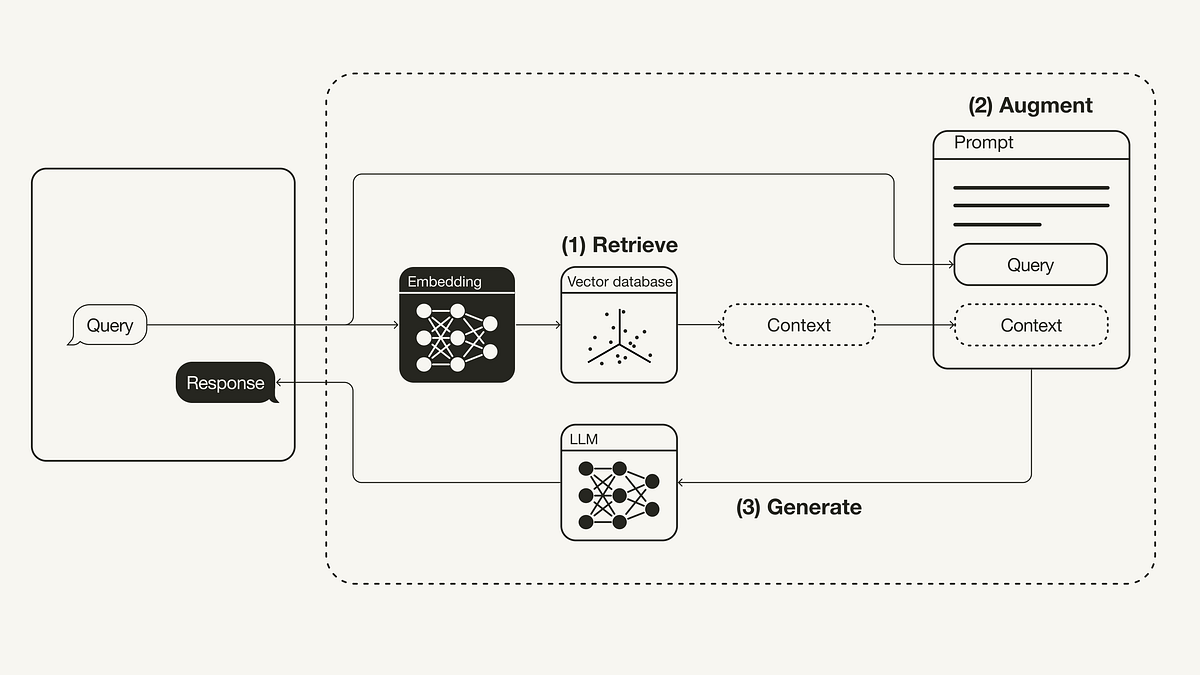
O RAG, facilitado e padronizado pelo LangChain, é um pipeline elegante, mas complexo, que funciona em duas fases principais: a Fase de Indexação (Offline) e a Fase de Consulta (Online).
Fase 1: A Criação do Conhecimento (Indexação)
Esta fase é a preparação da sua base de dados externa, a "memória de longo prazo" da sua aplicação, e envolve três passos orquestrados pelo LangChain:
1. Loading (Carregamento)
O primeiro passo é ingerir a informação. O LangChain oferece diversos Document Loaders (PDFLoader, DirectoryLoader, WebBaseLoader, etc.) que padronizam a forma como dados não estruturados (PDFs, documentos Word, páginas web, bases de dados) são lidos e convertidos em um formato de Document que o framework entende.
2. Splitting (Fragmentação)
É ineficiente e impraticável injetar um documento de 500 páginas no prompt do LLM. O Text Splitter do LangChain (como o RecursiveCharacterTextSplitter) divide grandes documentos em chunks (fragmentos) menores, de tamanho ideal (e.g., 500 a 1000 tokens), garantindo que cada fragmento mantenha o máximo de contexto semântico possível. Este passo é vital para a precisão do Retrieval.
3. Embedding e Storing (Incorporação e Armazenamento)
Cada chunk é então processado por um Embedding Model (OpenAIEmbeddings, HuggingFaceEmbeddings, etc.), que o transforma em um vetor – uma representação numérica de seu significado semântico. Esses vetores são então armazenados em um Vector Store (como Pinecone, ChromaDB, ou FAISS). É aqui que o texto se transforma em matemática, permitindo a busca por similaridade semântica, e não apenas por palavras-chave.
Fase 2: A Resposta Informada (Consulta)
Quando o usuário faz uma pergunta, a orquestração do LangChain é ativada para gerar uma resposta baseada na informação mais relevante:
4. Retrieval e Generation (Recuperação e Geração Aumentada)
-
Recuperação (Retrieval): A pergunta do usuário é transformada em um vetor (usando o mesmo Embedding Model). O Retriever (o componente de busca do LangChain) usa esse vetor para fazer uma pesquisa de vizinhos mais próximos no Vector Store, identificando e retornando os 3 a 5 chunks (fragmentos) mais semanticamente relevantes.
-
Aumento e Geração (Augmentation & Generation): O LangChain então monta um prompt final poderoso, que contém:
-
A pergunta original do usuário.
-
Instruções claras para o LLM (Prompt Template).
-
O Contexto completo, composto pelos chunks recuperados na etapa anterior.
-
O LLM recebe este prompt aumentado e é instruído a responder apenas com base no contexto fornecido.
A Mágica do LangChain: Chains de RAG
A verdadeira beleza do LangChain é como ele encapsula toda essa complexidade em uma Chain.
Em vez de escrever código para cada etapa do RAG (vetorização da consulta, busca, formatação do prompt), eu uso componentes prontos como a RetrievalQA Chain. Com poucas linhas de código, eu defino qual é o Retriever (minha base de conhecimento) e qual é o LLM, e o LangChain cuida de todo o fluxo de trabalho "Query -> Retrieve -> Augment -> Generate" para mim.
Além disso, o LangChain permite estratégias avançadas de retrieval que estou explorando:
-
Self-Query Retrieval: Permite que o LLM construa a query ideal para a busca, utilizando os metadados dos documentos para refinar o filtro antes da busca vetorial.
-
Multi-Vector Retrieval: Lida com a complexidade de diferentes representações de dados (e.g., vetorizar a tabela inteira vs. vetorizar o resumo da tabela).
Conclusão: RAG é Governança e Confiança
Para mim, o RAG não é apenas uma técnica; é uma questão de confiança e governança. Ao implementar o RAG via LangChain, garantimos que nossas aplicações:
-
Respondam com Evidência: É possível citar as fontes (os documentos de onde o chunk foi extraído), aumentando a auditabilidade.
-
Sejam Dinâmicas: A base de conhecimento pode ser atualizada em tempo real, sem a necessidade de retreinar o LLM.
Dominar o LangChain e, especificamente, as nuances do RAG, é o que permite aos engenheiros de IA entregar soluções que não apenas impressionam, mas que realmente resolvem problemas de negócios com precisão e responsabilidade.