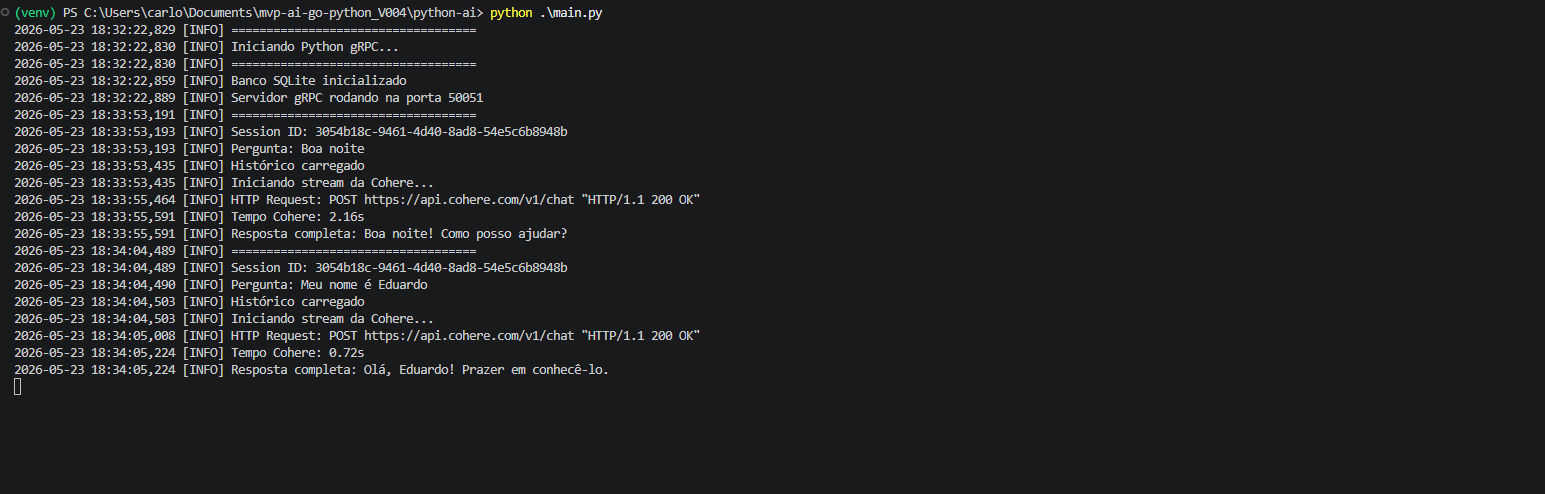
Huhuuu, finalmente tenho o prazer de apresentar o primeiro protótipo do MVP: Neural Chat MVP • Go + Python + gRPC + Cohere. Comecei o desenvolvimento, precisamente em 03/05/2026 e, depois de algumas madrugadas em claro e muito café, coloquei o bicho de pé. Ele está rodando redondo e provando o potencial de juntar duas frentes que muita gente acha que disputam espaço, mas que no meu desenho arquitetural se completam perfeitamente: a velocidade bruta e concorrência do Go com a maturidade do ecossistema de Inteligência Artificial do Python.
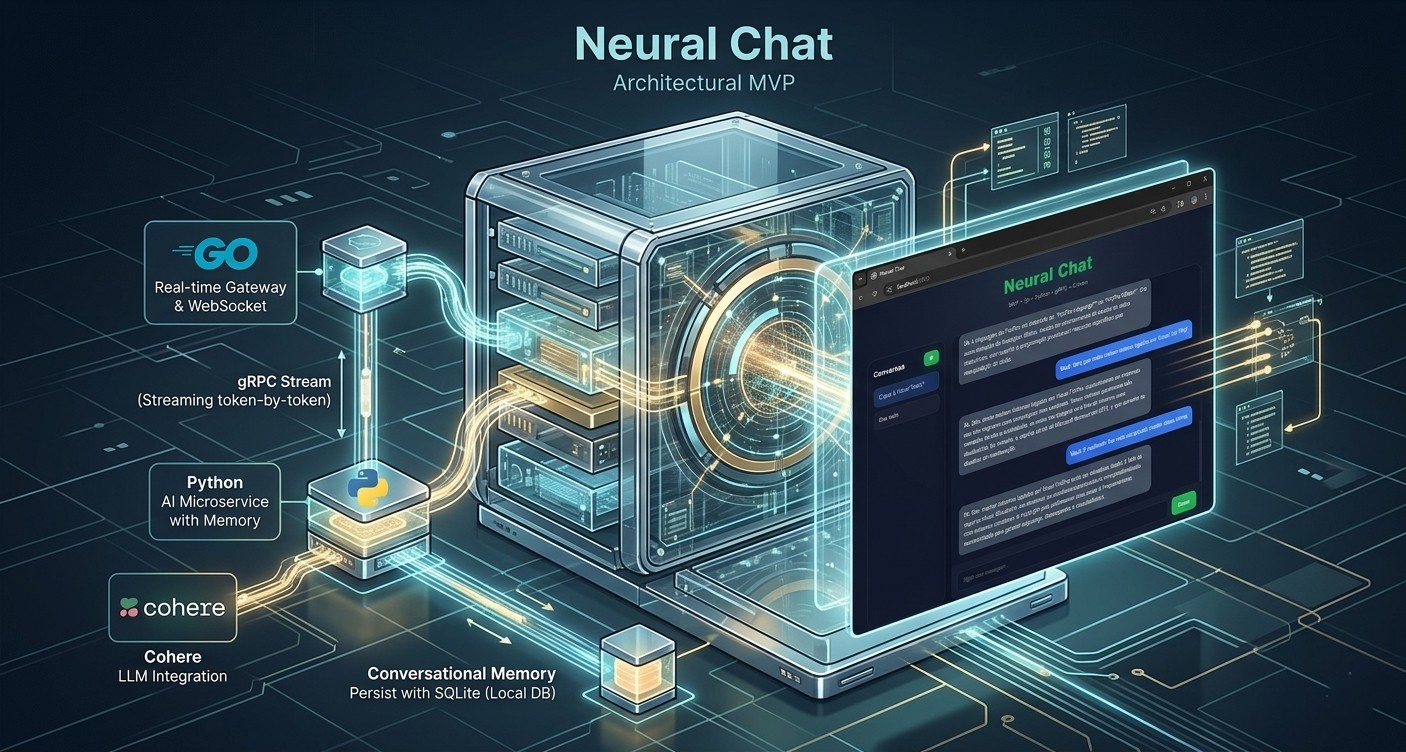
A minha ideia central quando idealizei o Neural Chat não era apenas fazer mais do mesmo, criando um clone de chat qualquer que bate em uma API de LLM de forma síncrona e joga o texto na tela de qualquer jeito. Como arquiteto do sistema, montei o design pensando no dia seguinte. Eu queria uma arquitetura distribuída, totalmente desacoplada, escalável por natureza e que aguentasse o tranco de streaming em tempo real token-by-token sem engasgar e sem misturar as responsabilidades.
Para estruturar o ecossistema de forma que eu possa evoluir o produto sem ter nenhum retrabalho de fundação, dividi o desenvolvimento em três grandes blocos independentes. Cada tecnologia entrou no meu fluxo fazendo exatamente aquilo em que é imbatível.
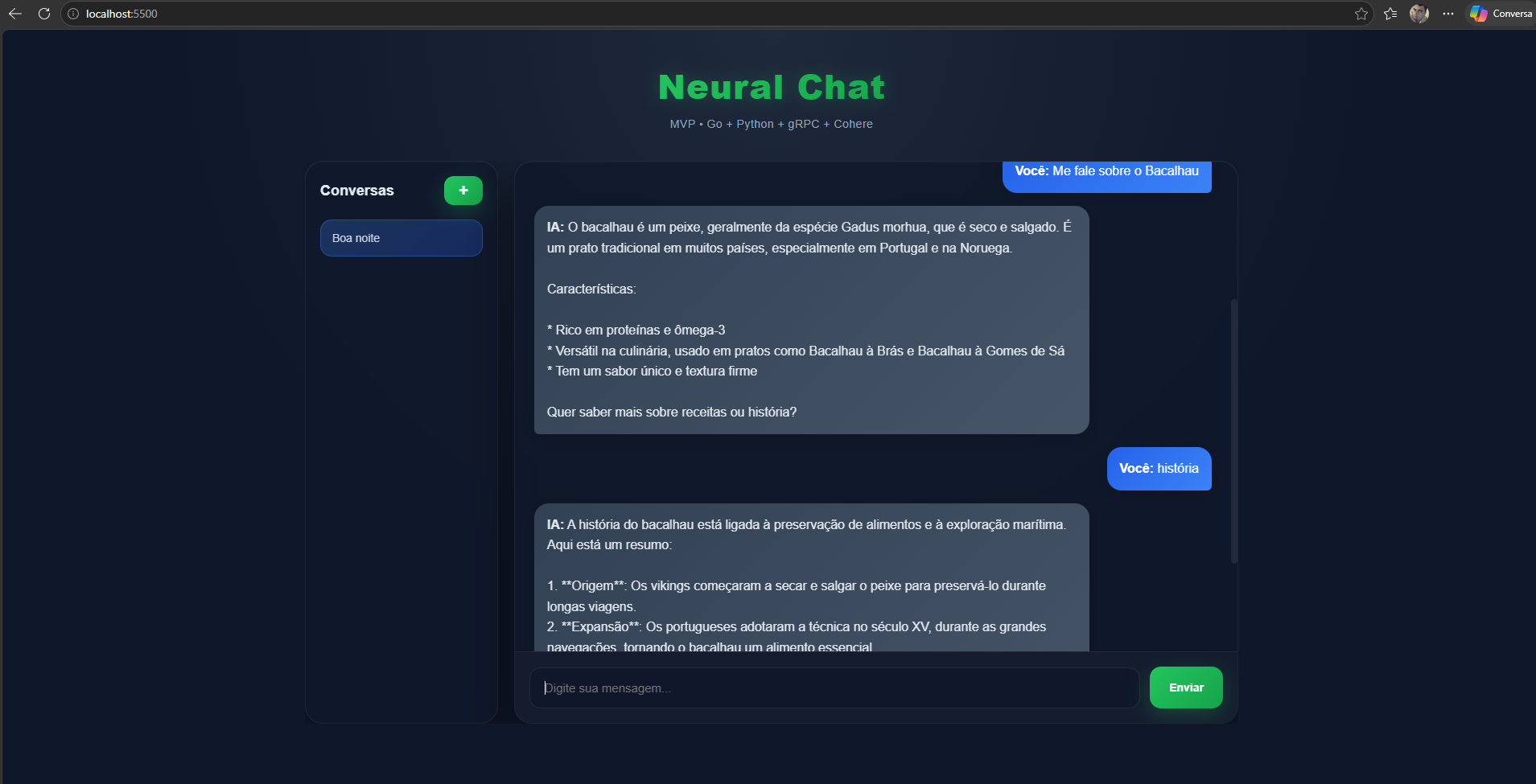
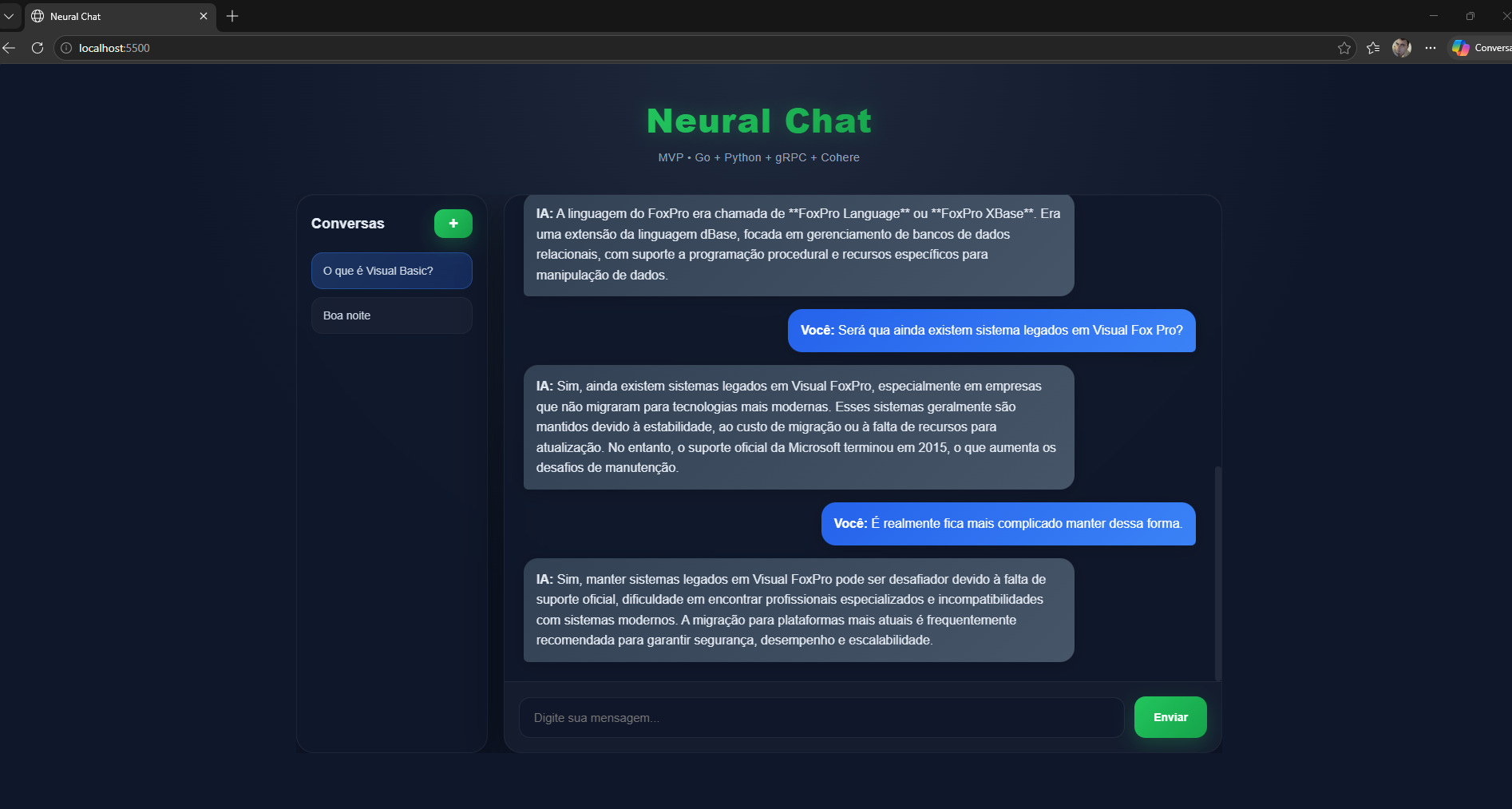
No Frontend, construí uma interface focada em experiência fluida. Implementei uma lógica que gera automaticamente uma sessão única via UUID e persiste esses dados direto no navegador do usuário. Isso significa que dá para dar um refresh na página e a conversa continua lá, intacta, enviando as mensagens estruturadas em JSON e sustentando uma conexão WebSocket aberta.
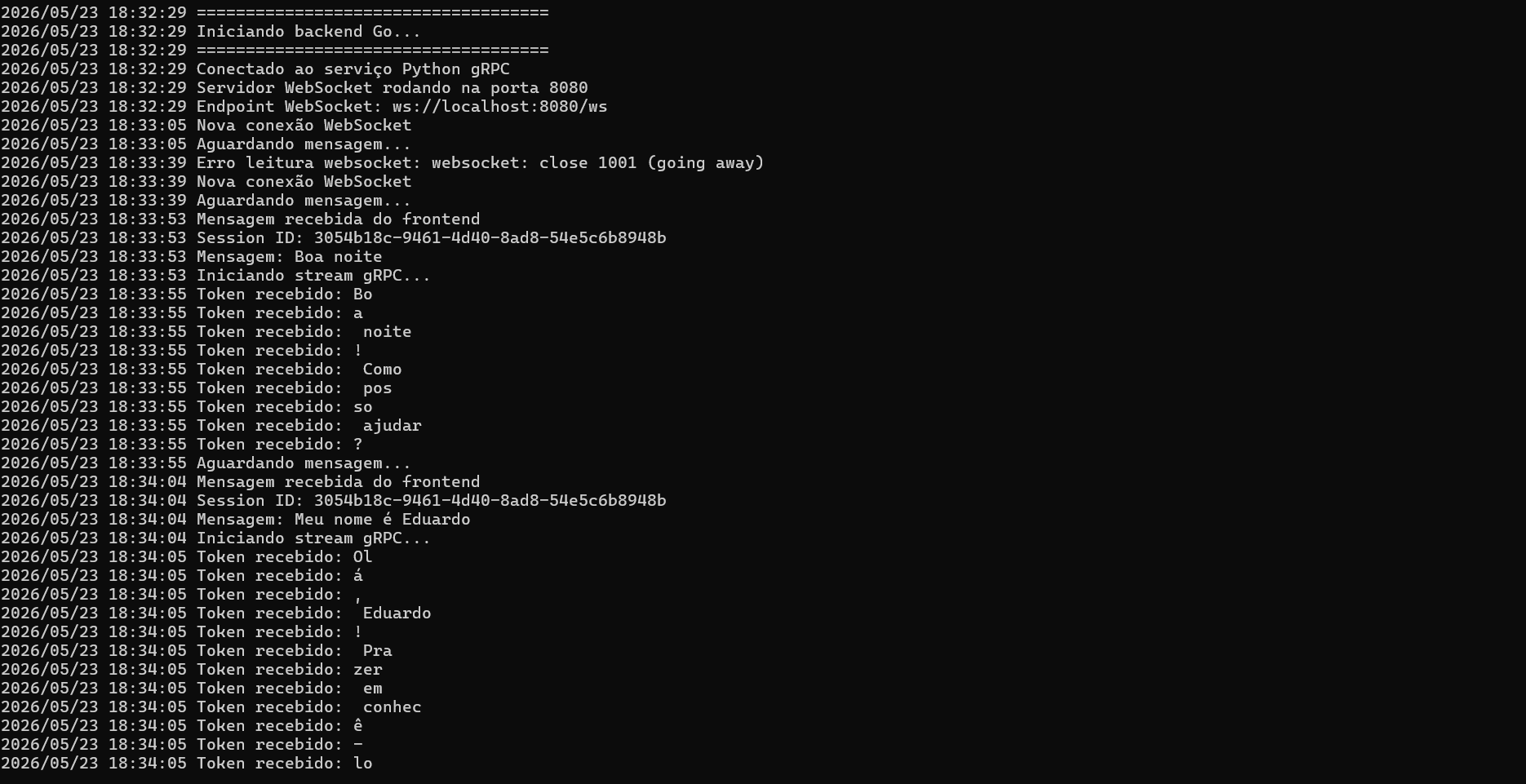
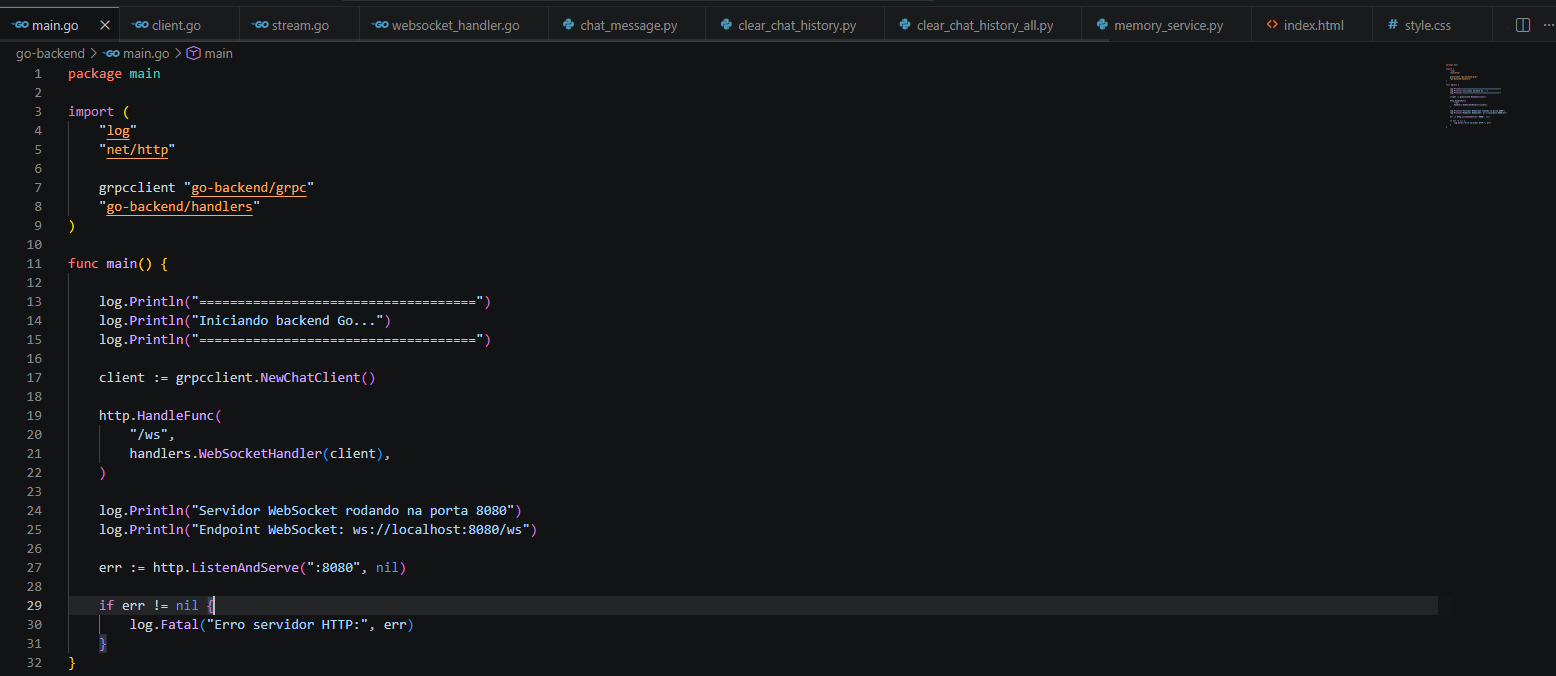
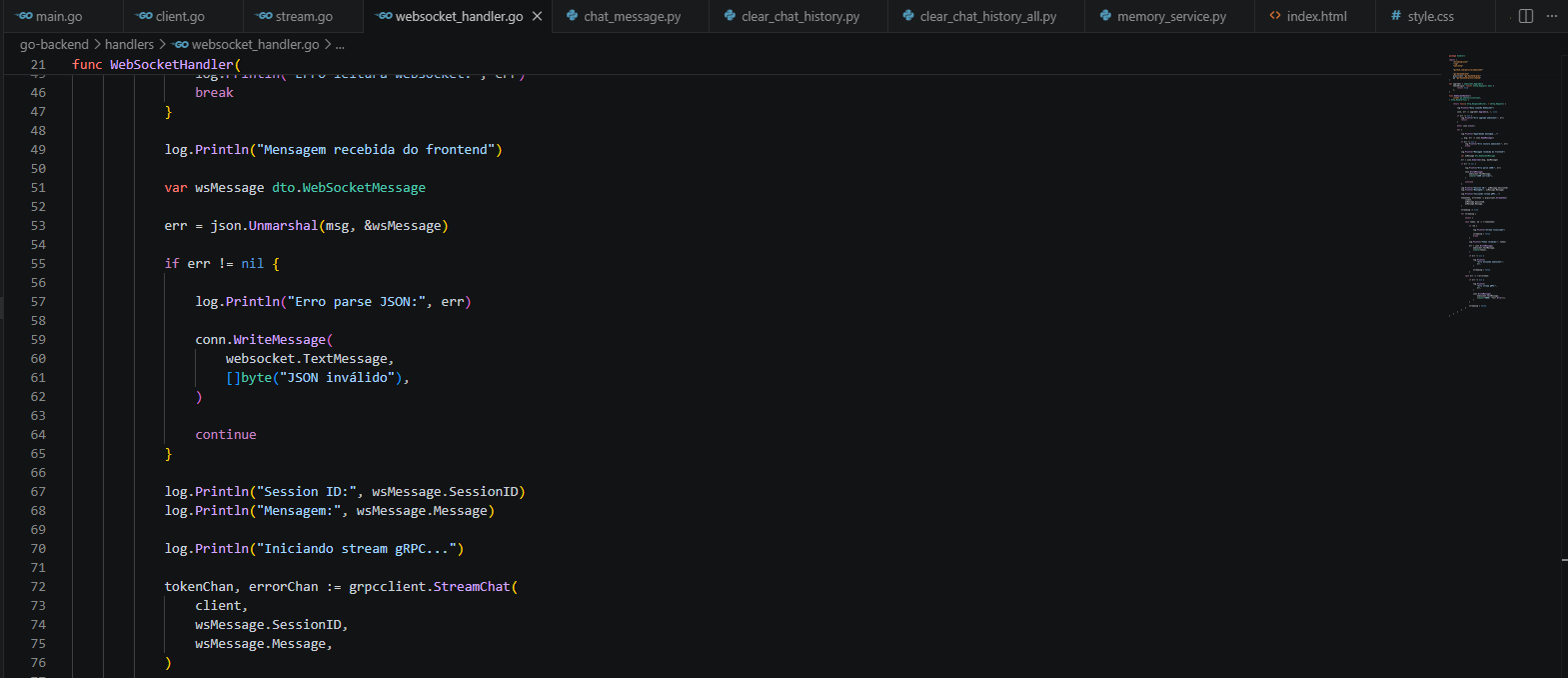
No Backend em Go, criei o meu Gateway de tempo real. Como preciso de alta performance para gerenciar conexões persistentes e concorrência, o Go foi a escolha natural para segurar o servidor WebSocket e manter o canal gRPC aberto com o meu microsserviço de IA. Deixei o Go totalmente agnóstico: ele não sabe o que é uma LLM, não gerencia memória e não guarda estado. Ele simplesmente recebe o prompt do usuário, despacha via gRPC para a outra ponta e, conforme o stream de resposta retorna, ele repassa cada token em tempo real para o frontend.
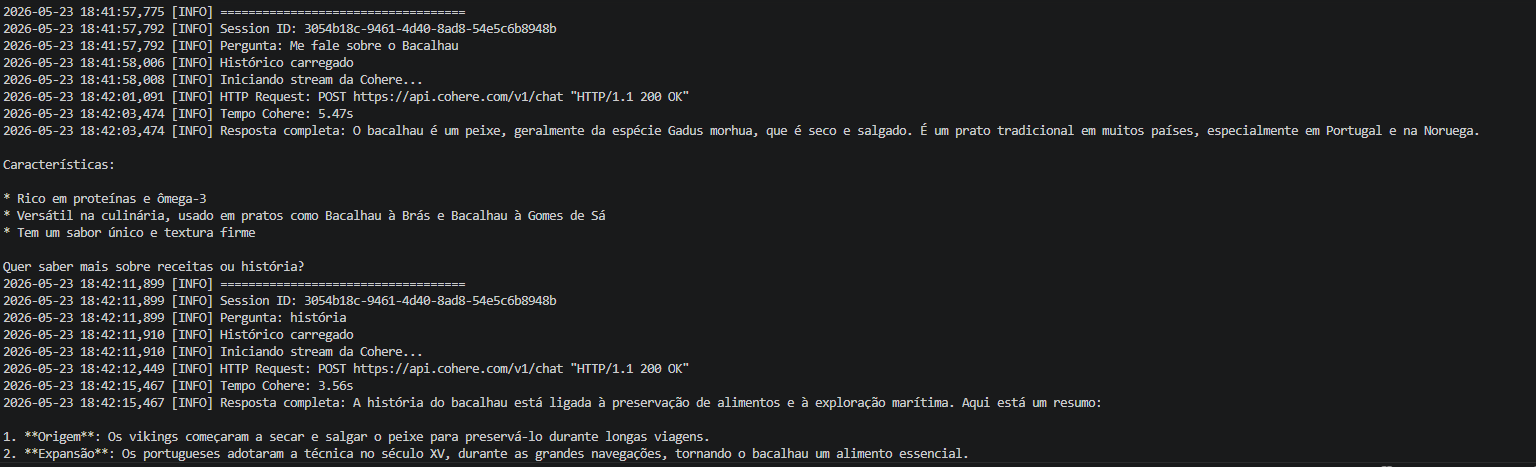
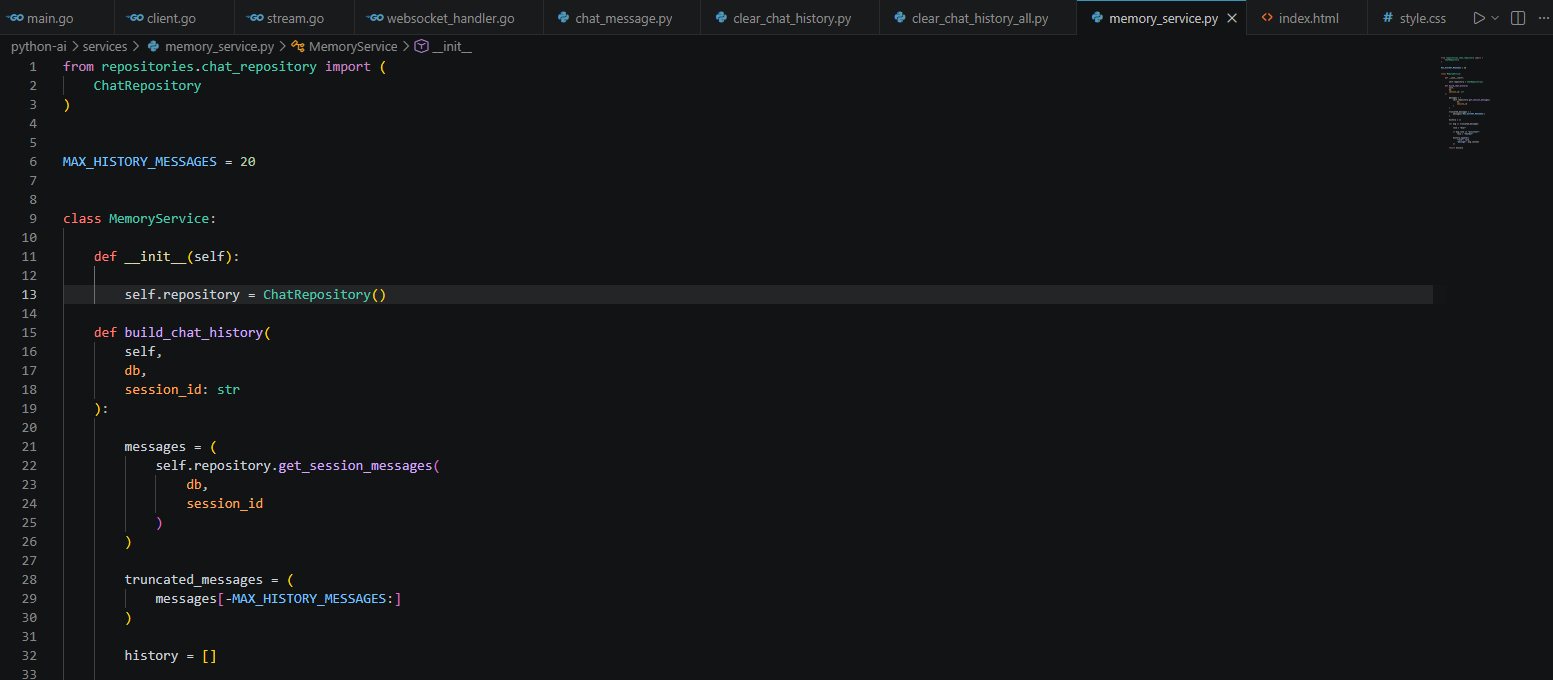
O Microsserviço em Python foi onde centralizei toda a inteligência conversacional do sistema. Desenvolvi essa camada para ser a única responsável por integrar com o modelo externo da Cohere, gerenciar a memória conversacional, persistir o histórico e montar o contexto exato que o modelo precisa para responder. Ele recebe a chamada limpa via gRPC vinda do Go, faz a mágica acontecer e devolve a resposta também por streaming gRPC de alta velocidade.
O fluxo geral que desenhei para a comunicação funciona de forma linear na ida: o Frontend bate no meu WebSocket, que joga para o Backend Go, que faz a chamada gRPC para o meu Python AI até chegar na Cohere. Na volta, para garantir aquela experiência de digitação em tempo real, fiz o caminho inverso de forma totalmente assíncrona: a Cohere cospe os dados no Python AI, que abre um gRPC Stream para o Go, que por sua vez empurra os tokens pelo WebSocket direto para o Frontend.
Para manter o meu microsserviço Python limpo, profissional e fácil de escalar, estruturei o código dividindo-o em camadas muito bem definidas. Criei o diretório database/ para isolar a conexão do banco; a pasta models/ para mapear as entidades; a camada repositories/ onde apliquei o Repository Layer para separar o acesso ao banco das regras de negócio; e a pasta services/ para isolar a lógica da memória conversacional.
A persistência da memória foi um desafio que resolvi usando o SQLite local. Montei o sistema para criar as tabelas de forma automática assim que o serviço sobe. Toda vez que o usuário interage, eu salvo a mensagem dele e a resposta da IA atreladas ao UUID daquela sessão. Quando chega um novo prompt, meu repositório busca o histórico completo no SQLite, o serviço monta o bloco de contexto atualizado e despacha para a Cohere. Com isso, garanti que a IA ganhasse continuidade e lembrasse do contexto da conversa.
Embora o sistema ainda seja um MVP, eu já cimentei a fundação preparando a arquitetura para suportar o próximo nível de escala. Do jeito que montei, o ecossistema já aceita múltiplos usuários simultâneos e múltiplas sessões por usuário nativamente. Se amanhã o volume estourar, a minha camada de repositório me permite migrar o SQLite para um cluster PostgreSQL trocando basicamente as configurações de conexão, sem que eu precise reescrever a lógica central de IA.
Deixei o terreno totalmente limpo e engatilhado para acoplar novos recursos que já mapeei no meu radar de arquitetura: autenticação de usuários, infraestrutura de RAG para o chat ler documentos internos, agentes autônomos, execução de ferramentas externas através de Function Calling, observabilidade com tracing de requisições, rate limit e filas de eventos distribuídas.
Como encerrei esse primeiro ciclo focado em validação ágil, deixei algumas frentes deliberadamente para as próximas sprints. No meu backend Go, falta subir logs estruturados, tracing e métricas de performance. Na parte de IA, vou trabalhar na geração de embeddings e no pipeline do RAG. E no frontend, a evolução vai ser criar o gerenciamento de múltiplas conversas históricas em uma barra lateral e melhorar os loading states.
O resultado final desse MVP me entregou exatamente o que eu buscava: uma arquitetura distribuída sólida, streaming de baixíssima latência e uma separação impecável de responsabilidades onde cada tecnologia brilha no que faz de melhor.
Se você está quebrando a cabeça tentando enfiar lógica complexa de LLM e conexões de tempo real dentro de um monolito pesado, o meu conselho é separar as coisas. Essa arquitetura que montei unindo Go no roteamento de dados e Python na inteligência provou ser o caminho definitivo para sistemas de IA de alta performance.
Em breve vou disponibilizar o projeto no meu Git Hub.
Algumas telas: