Minha Perspectiva Sobre o Caos Controlado dos LLMs
Desde que os Large Language Models (LLMs) como GPT-4, Gemini e Claude saíram do laboratório para o mundo real, a comunidade de desenvolvimento mergulhou em um frenesi de inovação. A capacidade de gerar texto coerente e relevante abriu um universo de possibilidades. No entanto, rapidamente percebemos que a simples chamada de API a um LLM não é suficiente para construir aplicações robustas, escaláveis e, acima de tudo, inteligentes. É aí que a orquestração de LLMs entra em cena, e, na minha experiência, ela é a verdadeira virada de jogo.
Orquestrar um LLM é muito mais do que apenas um wrapper de API. É a arte e a ciência de guiar o fluxo de trabalho da IA, delegando tarefas, gerenciando o contexto, integrando dados externos e, fundamentalmente, transformando um modelo de linguagem poderoso em um agente de resolução de problemas. Sem orquestração, um LLM é um gênio isolado; com ela, ele se torna o cérebro de uma solução complexa e multifacetada.
Por Que a Orquestração é Indispensável
Por que não podemos simplesmente fazer uma única chamada ao modelo? A resposta reside na natureza intrínseca dos problemas que estamos tentando resolver:
-
Limitações de Conhecimento e Alucinação: Os LLMs são treinados em datasets gigantescos, mas seu conhecimento é estático (limitado ao corte temporal do treinamento). Para responder a perguntas sobre dados internos, documentos recentes ou informações em tempo real, o LLM precisa acessar fontes de dados externas.
-
Complexidade da Tarefa (Multi-step): Tarefas do mundo real raramente são resolvidas em uma única etapa. Pense em um assistente de viagens: ele precisa (1) entender a intenção, (2) buscar passagens/hotéis em uma API, (3) sumarizar as opções e (4) formatar a resposta. Isso exige um encadeamento lógico de ações.
-
Gerenciamento de Contexto (Memória): Em interações longas, como chatbots conversacionais, o modelo precisa lembrar o que foi dito antes. Isso demanda mecanismos sofisticados de memória que alimentam as interações subsequentes.
-
Uso de Ferramentas (Agents): Em alguns casos, o LLM precisa decidir qual ferramenta usar para resolver um problema (e.g., uma calculadora, um buscador na web, um endpoint de API). O modelo se transforma em um agente de tomada de decisão.
A orquestração resolve todos esses desafios, e é neste ponto que o LangChain se estabeleceu como o padrão ouro da indústria.
LangChain: O Maestro da Orquestra de IA
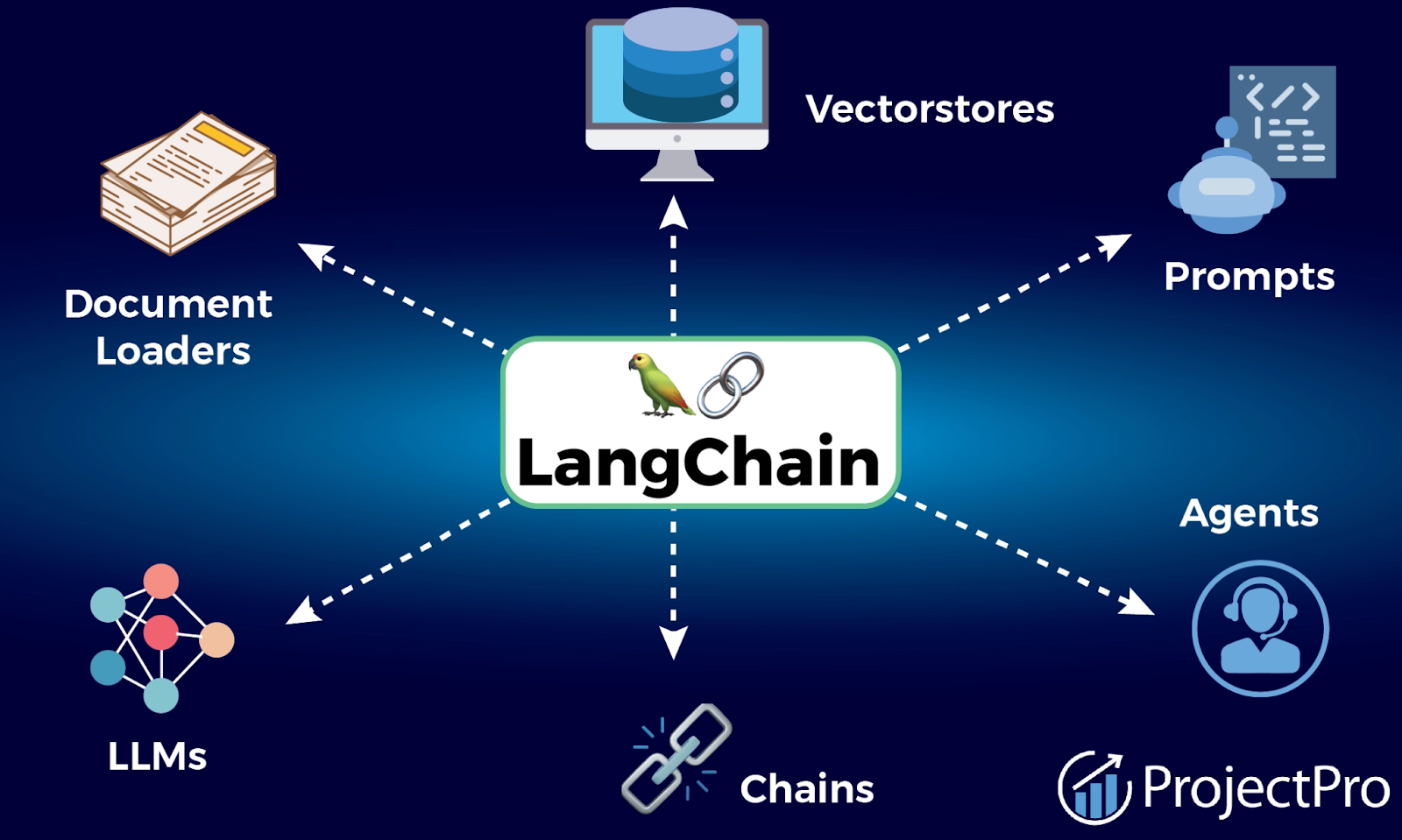
O LangChain é o framework modular que transformou minha abordagem ao desenvolvimento de aplicações com LLMs. Ele fornece os blocos de construção essenciais para orquestrar fluxos de trabalho complexos de forma elegante e escalável.
O que me impressiona no LangChain é a sua modularidade e a maneira como ele padroniza a interação, abstraindo as complexidades de diferentes fornecedores de LLMs (OpenAI, Google, Cohere, etc.). Ele se baseia em seis módulos principais que, juntos, formam a espinha dorsal de qualquer aplicação sofisticada:
1. Modelos (Models)
O LangChain fornece uma interface uniforme para interagir com qualquer LLM. Isso permite que eu troque o modelo subjacente (e.g., de GPT-3.5 para GPT-4, ou para um modelo open-source como LLaMA) com o mínimo de alteração de código, garantindo a flexibilidade e a resiliência da minha arquitetura.
2. Prompts
A gestão de prompts é crucial, e o LangChain facilita a criação de templates reutilizáveis e dinâmicos. Isso é vital para garantir a consistência e a otimização do output do LLM, ajustando as variáveis de entrada de forma programática.
3. Cadeias (Chains)
As Chains são o coração da orquestração. Elas permitem que eu combine LLMs e outros componentes em uma sequência lógica. A saída de um componente se torna a entrada do próximo, permitindo resolver problemas complexos passo a passo. A mais fundamental, a LLMChain, liga um Prompt Template a um LLM, mas é a composição de cadeias mais elaboradas que realmente desbloqueia o potencial.
4. Recuperação (Retrieval) e RAG
Este é, para mim, o módulo mais poderoso. O LangChain simplifica a implementação do padrão Generation Augmented Retrieval (RAG). Ele lida com o carregamento de documentos (PDFs, HTML, etc.), a divisão em chunks semânticos, a criação de embeddings (representações vetoriais) e o armazenamento em Vector Stores (como FAISS ou Pinecone). No momento da consulta, o Retriever busca as informações mais relevantes e as injeta no prompt do LLM, combatendo a alucinação e garantindo respostas contextualizadas e factuais.
5. Memória (Memory)
Para criar chatbots úteis, precisamos de memória. O LangChain oferece diversos tipos de memória (como a ConversationBufferWindowMemory ou a ConversationSummaryBufferMemory) que gerenciam o histórico da conversa, assegurando que o LLM mantenha o contexto de longo prazo sem exceder o limite de tokens do prompt.
6. Agentes (Agents)
Este módulo eleva a orquestração a um nível superior. Os Agents permitem que o LLM não apenas gere texto, mas também tome decisões e execute ações. Eu forneço ao Agente um conjunto de Tools (ferramentas como APIs ou funções Python), e o LLM, usando um processo de raciocínio (muitas vezes baseado no framework ReAct), decide a sequência de ações necessárias para alcançar um objetivo. É aqui que o LLM se transforma em um "cérebro" autônomo.
Conclusão: O Diferencial Competitivo
A verdade é que a orquestração de LLMs, facilitada por frameworks maduros como o LangChain, não é mais um luxo — é um requisito.
Ao internalizar o LangChain, ganhamos a capacidade de construir sistemas que são sensíveis ao contexto, capazes de raciocínio em múltiplos passos e conectados ao mundo exterior (via RAG e Agents). Em um mercado onde a IA generativa está se tornando commoditizada, a experiência técnica em orquestração é o que realmente separa um protótipo de laboratório de uma solução empresarial confiável, escalável e de alto valor. Estou convicto de que dominar o LangChain é dominar o futuro da engenharia de IA.