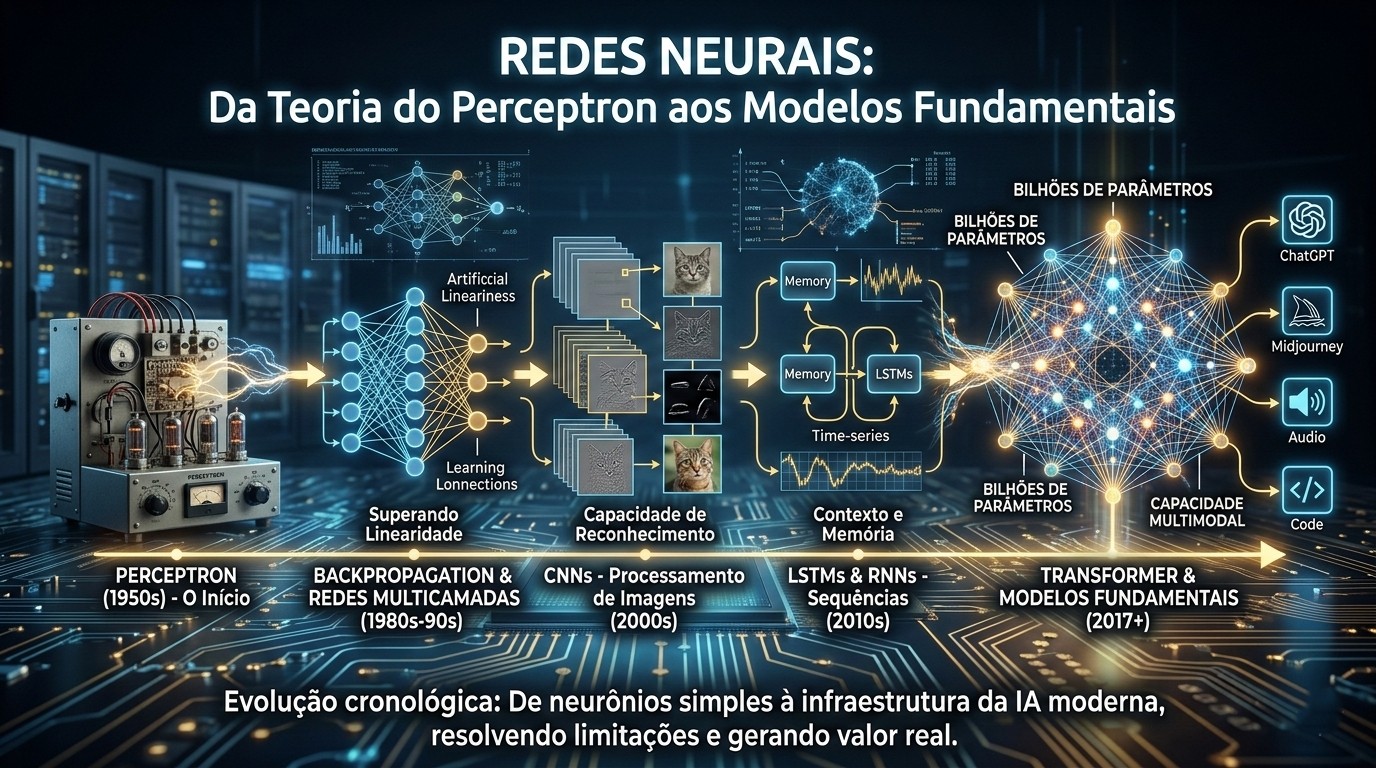
Quando falamos em Inteligência Artificial moderna, inevitavelmente estamos falando de redes neurais. O que hoje sustenta modelos capazes de escrever textos, interpretar imagens, dirigir veículos e prever padrões complexos nasceu de uma pergunta simples: é possível modelar matematicamente o funcionamento do cérebro humano? Neste artigo, apresento uma visão cronológica e técnica da evolução das redes neurais, desde os primeiros experimentos até os modelos mais avançados da atualidade, passando pelos perceptrons, suas limitações, seus sucessores e o que temos hoje em termos de estado da arte.
O Início: A Inspiração Biológica
A base conceitual das redes neurais surge em 1943, quando Warren McCulloch e Walter Pitts publicam um artigo propondo um modelo matemático simplificado do neurônio biológico. A ideia era representar neurônios como unidades lógicas que recebem sinais de entrada, aplicam uma função de ativação e produzem uma saída binária. Esse modelo não aprendia, mas estabeleceu o alicerce conceitual: processamento distribuído e paralelo inspirado no cérebro.
Em 1949, Donald Hebb propôs a famosa regra de aprendizagem conhecida como “Hebbian learning”: neurônios que disparam juntos, fortalecem suas conexões. Esse conceito introduziu a noção de ajuste de pesos com base na experiência, um princípio central para o aprendizado em redes neurais.
O Perceptron: O Primeiro Modelo Treinável
Em 1957, Frank Rosenblatt apresentou o Perceptron. Esse foi o primeiro modelo de rede neural capaz de aprender a partir de dados. O perceptron é essencialmente um classificador linear. Ele recebe um vetor de entradas, multiplica cada entrada por um peso, soma tudo e aplica uma função de ativação degrau.
Formalmente, temos:
Saída = função_degrau(w1x1 + w2x2 + ... + wnxn + b)
O treinamento ocorre ajustando os pesos com base no erro da predição. Se o modelo classifica errado, os pesos são atualizados na direção que reduz o erro. Esse algoritmo simples permitiu resolver problemas linearmente separáveis, como a classificação AND e OR.
Entretanto, em 1969, Marvin Minsky e Seymour Papert publicaram o livro “Perceptrons”, demonstrando matematicamente que o perceptron de camada única não consegue resolver problemas não linearmente separáveis, como o clássico problema XOR. Essa limitação causou grande desânimo na comunidade científica e levou ao primeiro “inverno da IA”.
A Superação do XOR: Redes Multicamadas
A grande limitação do perceptron era estrutural: apenas uma camada linear não consegue modelar fronteiras de decisão não lineares. A solução foi adicionar camadas ocultas, criando o que chamamos de Multi-Layer Perceptron (MLP).
Embora a ideia de múltiplas camadas já existisse, o grande avanço veio na década de 1980 com a popularização do algoritmo de retropropagação do erro (backpropagation), formalizado por David Rumelhart, Geoffrey Hinton e Ronald Williams em 1986.
O backpropagation utiliza cálculo diferencial e regra da cadeia para propagar o erro da saída para as camadas anteriores, ajustando todos os pesos da rede de forma eficiente. Isso transformou redes multicamadas em modelos treináveis de forma prática.
A partir desse momento, redes neurais tornaram-se aproximadores universais de funções: teoricamente, uma rede com pelo menos uma camada oculta e número suficiente de neurônios pode aproximar qualquer função contínua.
Anos 1990: Especialização das Arquiteturas
Na década de 1990 surgiram arquiteturas especializadas para diferentes tipos de dados.
Redes Neurais Convolucionais (CNNs)
Yann LeCun desenvolveu as Convolutional Neural Networks (CNNs), especialmente para reconhecimento de imagens. O modelo LeNet-5 foi aplicado com sucesso para leitura de dígitos manuscritos. A grande inovação das CNNs foi o uso de convoluções, compartilhamento de pesos e redução de dimensionalidade, explorando a estrutura espacial das imagens.
Redes Neurais Recorrentes (RNNs)
Para dados sequenciais, como texto e séries temporais, surgiram as Redes Neurais Recorrentes. Diferentemente das redes feedforward, as RNNs possuem conexões que realimentam o estado interno, permitindo memória temporal.
Contudo, RNNs tradicionais sofriam com o problema do gradiente que desaparece ou explode. Para resolver isso, surgiram variações como LSTM (Long Short-Term Memory), proposta por Hochreiter e Schmidhuber em 1997, e posteriormente GRU (Gated Recurrent Unit). Essas arquiteturas introduziram mecanismos de portas para controlar o fluxo de informação e preservar dependências de longo prazo.
O Segundo Inverno e a Virada do Deep Learning
Durante os anos 1990 e início dos 2000, redes neurais perderam espaço para métodos como SVMs e modelos probabilísticos. O treinamento era lento, os dados eram limitados e o hardware era restrito.
A virada começou por volta de 2006, quando Geoffrey Hinton propôs métodos de pré-treinamento camada a camada usando Deep Belief Networks. Mas o grande marco ocorreu em 2012, no desafio ImageNet, quando Alex Krizhevsky, Ilya Sutskever e Hinton apresentaram a AlexNet, uma CNN profunda treinada com GPUs, que superou drasticamente os métodos tradicionais em visão computacional.
Esse evento consolidou o Deep Learning como abordagem dominante.
Transformers: A Revolução na Modelagem de Sequências
Em 2017, pesquisadores do Google publicaram o artigo “Attention Is All You Need”, introduzindo a arquitetura Transformer. A principal inovação foi o mecanismo de atenção, que permite que o modelo avalie a relevância de cada elemento da sequência em relação aos outros, eliminando a necessidade de recorrência.
Os Transformers trouxeram:
Processamento paralelo mais eficiente que RNNs.
Melhor captura de dependências de longo alcance.
Escalabilidade massiva com grandes volumes de dados.
A partir daí surgiram modelos como BERT, GPT, T5 e diversos outros. Esses modelos são treinados em enormes volumes de dados e ajustados para tarefas específicas. A evolução levou ao conceito de modelos fundamentais (foundation models), capazes de generalizar para múltiplas tarefas.
Redes Neurais Modernas e Modelos de Grande Escala
Hoje estamos na era dos Large Language Models (LLMs) e modelos multimodais. Esses sistemas possuem bilhões ou até trilhões de parâmetros.
As principais características das redes modernas incluem:
Escala massiva de parâmetros.
Treinamento auto-supervisionado.
Aprendizado por reforço com feedback humano.
Capacidade multimodal (texto, imagem, áudio e vídeo).
Uso intensivo de GPUs e TPUs.
Treinamento distribuído em larga escala.
Além disso, técnicas como fine-tuning, transfer learning, quantização e distilação permitem adaptar modelos gigantes para aplicações específicas com custo reduzido.
Perceptron e Seus Sucessores: Uma Linha Evolutiva
Se organizarmos a evolução a partir do perceptron, podemos visualizar a seguinte progressão:
Perceptron de camada única: classificador linear.
Perceptron multicamada (MLP): capacidade de modelar não linearidades.
CNNs: especialização para dados espaciais.
RNNs, LSTMs e GRUs: especialização para sequências.
Transformers: atenção como mecanismo central.
Modelos Fundamentais: generalização em larga escala e multiuso.
Cada estágio resolveu uma limitação estrutural do anterior: linearidade, incapacidade de memória, limitação de paralelização, entre outras.
Estado da Arte Atual
Hoje as redes neurais estão integradas em praticamente todos os setores: saúde, finanças, indústria, direito, segurança, ciência e engenharia.
As fronteiras atuais de pesquisa envolvem:
Modelos multimodais unificados.
Redução de consumo energético.
Treinamento mais eficiente.
IA explicável.
Modelos menores e mais eficientes (edge AI).
Integração com agentes autônomos e sistemas de tomada de decisão.
Há também um movimento forte em direção à segurança, alinhamento e governança de modelos, especialmente considerando o impacto social e econômico dessas tecnologias.
Conclusão
A história das redes neurais é uma história de ciclos: entusiasmo, frustração, avanços matemáticos, limitações computacionais e, finalmente, consolidação tecnológica. O perceptron foi o ponto de partida. As redes multicamadas trouxeram poder expressivo. O deep learning trouxe escala. Os transformers trouxeram eficiência e generalização massiva.
Hoje, as redes neurais deixaram de ser apenas uma técnica acadêmica e tornaram-se infraestrutura digital crítica. Entender sua evolução não é apenas compreender um campo da computação, mas entender uma das principais forças tecnológicas do nosso tempo.